铺天盖地的中转站,提供的 Claude 到底是什么?

最近 Claude Code 的中转站越来越多。
Claude 专线、Sonnet 高速、Opus 稳定、官转线路、逆向号池、混合池、共享池、专属池,各种说法铺天盖地。
价格不同,名字不同,套餐不同,群里宣传的口径也不同。但是前台界面看起来都差不多:你自己创建一个 key,然后使用中转站提供的 base url,把 Claude Code 跑起来。

在国内聊 Claude,先得把使用场景说清楚。
考虑到 Anthropic 官方对中国用户的使用限制,国内企业很少会把 Claude 放进正式生产环境。真正严肃的线上业务,大多会选择国产模型,或者接入路径相对清晰的 GPT 类模型。
国内大量 Claude 需求,主要集中在 Claude Code 这样的 coding 场景里。
Claude Code 能读项目、改代码、跑测试、处理报错、继续修问题。对很多开发者来说,它已经接近一个半自动 coding agent。
官方接入有现实限制,Claude Code 的需求又真实存在。中转站就在这个缝隙里长了出来。
中转站确实解决了一部分可用性问题。
但它也带来一个更麻烦的问题。
你在 Claude Code 里用到的 Claude,背后到底是一条什么链路?
国内用 Claude,主要发生在 Claude Code 里
Claude 在 coding 场景里的体验,确实有吸引力。
它写代码时的结构感、处理复杂上下文的能力、修 bug 时顺着根因往下走的习惯,都让很多开发者很难回头。
Claude Code 又进一步放大了这种体验。
它会进入项目目录,读文件,理解结构,制定修改计划,调用工具,编辑代码,跑测试,再根据报错继续调整。整个过程更像一个持续执行任务的开发助手。
这也是为什么国内开发者会大量寻找 Claude Code 的可用入口。
官方路径不好走,中转站就成了现实选择。
有些中转站做得确实能用。速度不错,价格也能接受,Claude Code 跑起来之后,开发效率提升很明显。
但中转站口中的“Claude”并不总是一回事。
它可能来自订阅号池,也可能来自 IDE 反代、云厂资源或者原厂券资源。前台看起来只是一个模型名,后面可能是完全不同的资源结构。
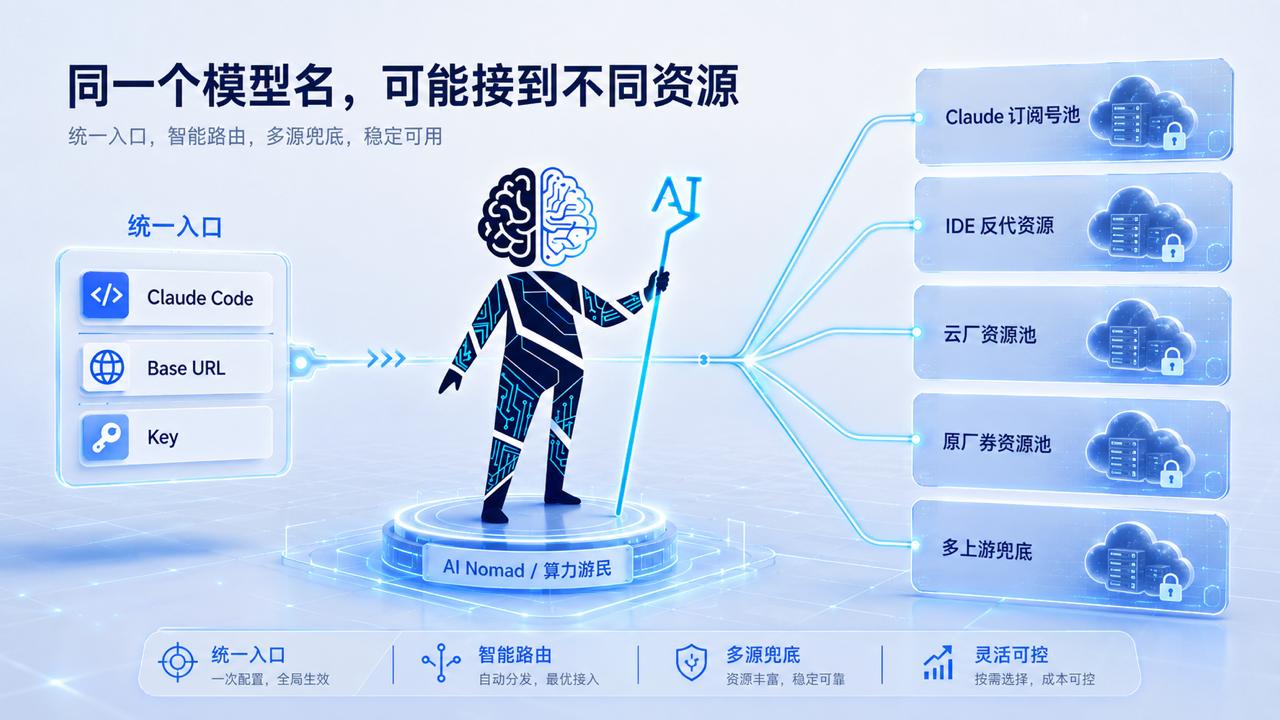
这些差异,最终都会落到 Claude Code 的体验上。
Claude Code 最怕频繁打断心流
Claude 中转站基本都不会提供严格 SLA 保证。
这也符合现在的市场状态。Claude 目前是卖方市场,资源紧张,官方接入限制又多。很多时候,能稳定用上已经不错了。
所以开发者对中转站的期待,其实没有那么夸张。
Claude Code 更像开发工具链的一部分。大家通常不会要求它做到四个九、五个九。
偶尔一次请求失败,Claude Code 自己 retry 一下,或者用户重新发一次,很多人都能接受。
真正难受的是频繁抽风。
Coding 场景是一段连续工作流。Claude Code 可能已经读完项目、改了一批代码,准备根据测试结果继续修。这时候链路一断,开发者也要跟着重新判断任务状态。
如果这种中断偶尔发生,还能忍。一天里反复发生,体验会非常糟糕。

Claude Code 场景里的稳定性,更接近开发者心流里的连续性。
它不一定要像生产系统一样追求极高可用,但至少要让一个开发任务能顺畅跑完。首 token 慢一点可以忍,高峰期偶尔抖一下也可以忍。长任务跑一半频繁断掉,工具调用经常卡住,retry 之后状态变乱,这些会直接影响开发效率。
同样叫 Claude,背后可能是不同资源
用户在后台看到的,通常只是一个模型名,比如 Claude Sonnet、Claude Opus,或者一个被包装成 Claude Code 可用的模型入口。
但中转站背后的资源来源可能完全不同。
它可能来自订阅号池,也可能来自 IDE 反代、云厂资源池、原厂券资源池,或者多个上游资源拼出来的混合池。前台看起来只是一个模型名,后面却可能是完全不同的资源结构。
同样叫 Claude,背后可能是完全不同的资源结构。
这个差异不一定能通过几轮对话看出来。很多时候,它更直接体现在 Claude Code 的可用性上,比如排队、超时、长任务中断、账号池风控、工具调用稳定性。
Claude Code 是连续任务。它会读文件、改代码、调用工具、跑测试。中间任何一个环节资源不稳,都会影响整个开发任务。
用户表面上买的是 Claude,实际接入的是背后一整套资源组织方式。
这才是中转站最值得拆开的地方。
中转站更像多层资源分发体系
很多人以为自己找的是 Claude 资源方。
实际情况可能更像一套渠道分发网络。
最上游可能是订阅号池、IDE 反代资源、云厂资源、原厂券资源,或者其他接入资源。中间可能有资源整合方,把不同资源池做成统一 API。再往下才是负责面板、套餐、收款、key 管理和用户群维护的渠道商。最后才到 Claude Code 用户手里。
这个结构和传统 SaaS 采购很不一样。
用户以为自己在买一个模型 API,实际买到的是一条层层包装后的调用链路。
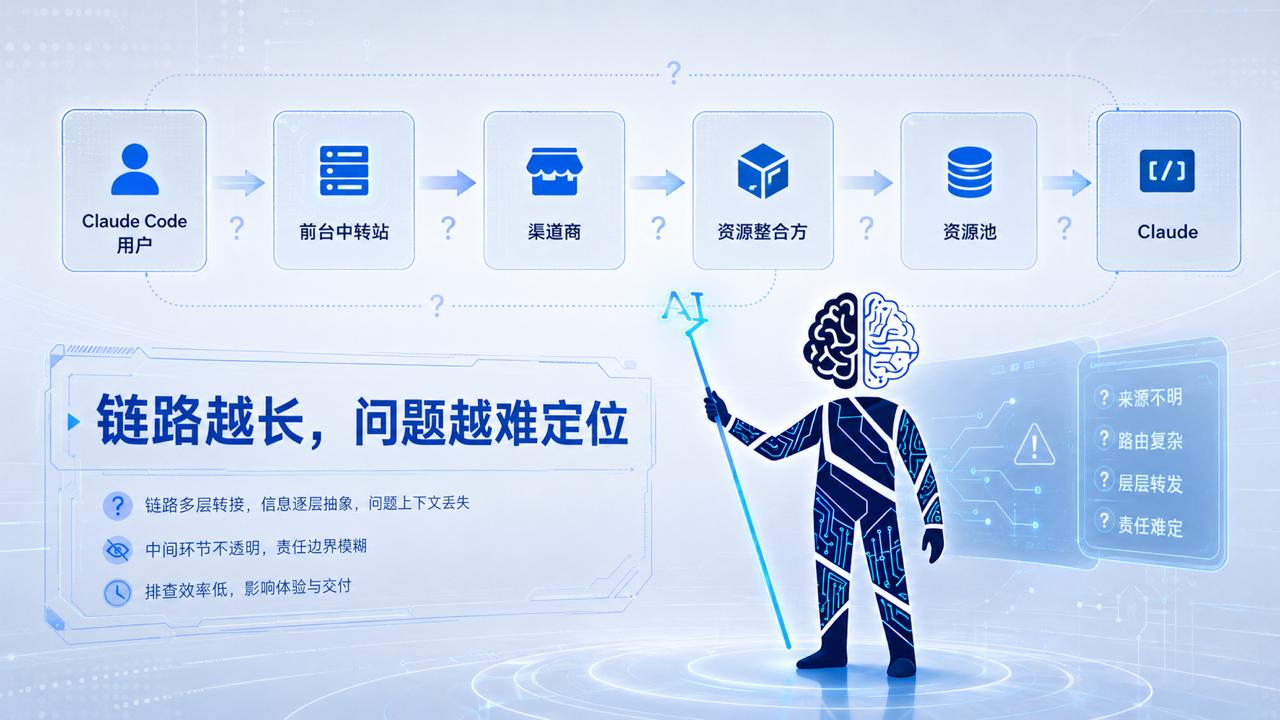
前台中转站可能无法完全解释资源调度。它知道自己接了哪个上游,但未必知道上游背后还有几层,也未必知道最终请求到底落到哪个资源池。
多上游兜底看起来更稳,但不一定真的分散风险。不同渠道可能最终来自同一个源头,一旦源头波动,多个平台会一起变慢、报错、排队或者不可用。
链路越长,问题越难定位。Claude Code 跑到一半断了,失败可能来自前台网关、渠道商、资源整合方、号池风控、IDE 反代资源、云厂额度限制,或者原厂侧策略变化。用户看到的是一次失败,背后的原因却可能隔了好几层。
很多中转站出问题时,只能给出很模糊的解释,比如“上游波动”“资源紧张”“正在调整”“晚高峰拥堵”。这些解释有时是真的,但用户很难知道问题到底发生在哪一层。
链路越长,模型体验、稳定性和故障原因就越难看清。
更麻烦的是链路会变
中转站背后的资源结构复杂,还会动态变化。
今天和明天可能走的不是同一个资源池。平峰和高峰可能走的也不是同一条上游。资源紧张、号池风控、上游故障、服务商扩容或者换供应商,都会改变用户实际用到的链路。
用户前台看到的模型名、base url 和 key 通常不会变。
模型名没变,不代表背后的链路没变。
这会带来一种很难解释的体验。前几天用起来很顺,突然开始排队;昨天还能跑完的任务,今天频繁中断;有时感觉“还是 Claude”,有时又觉得模型手感不太对。
这类变化很难归因。
可能是中转站自己的网关问题,可能是上游资源池波动,可能是号池风控,可能是高峰期调度策略变化,也可能是更上游的源头资源发生变化。
Claude Code 用户能感受到的,通常只是速度、任务连续性和模型手感的变化。至于问题发生在哪一层,用户很难知道。
这也是为什么中转站市场会有很强的口碑波动。一个站今天被推荐,过几天又被骂;一个套餐刚开始很好用,用一段时间就变差。很多时候,大家只是在不同时间、不同套餐、不同上游链路里,体验到了不同的 Claude。
Claude Code 里的真假,很难靠一次测试判断
很多人想找一种方法,快速判断中转站给的是不是真 Claude。
这个想法很正常。中转站太多,名词太多,价格差异也很大,用户当然想要一个简单结论。
但 Claude Code 场景里,这件事很难。
开发者说一个模型“像 Claude”,很多时候靠的是长期使用形成的手感。它改代码的节奏、理解项目的方式、处理上下文的能力、工具调用中的稳定性,确实会暴露一些差异。
但这些差异很难变成一个简单、稳定、可复现的测试标准。
一次回答像,不代表长期都像。
一个简单任务表现好,不代表复杂任务也稳。
今天测出来没问题,不代表明天背后的链路没有变化。
所以我不太相信“一眼鉴别真假 Claude”的方法。

单次测试最多只能提供线索,很难给出定论。
尤其是中转站背后资源会动态调度时,你测到的可能只是某个时间点、某条链路、某个资源池的表现。几小时之后,它可能已经换成另一条链路。
这才是 Claude 中转站最麻烦的地方。
用户需要判断真伪,但真伪很难被一次性证明。
用户真正能持续观察的,是速度、稳定性、链路透明度和故障解释能力。
真正能看的,往往是长期表现
中转站很少会把真实链路讲清楚。
资源来源、上游结构、调度策略、号池类型,这些都是核心商业信息。很多前台中转站自己也未必完全掌握上游细节。
所以用户很难直接问出答案,最后只能看长期使用表现。
对 Claude Code 来说,重点是复杂任务能不能稳定跑完,高峰期会不会明显劣化,连续工具调用会不会频繁中断,体验会不会隔几天大幅波动。
出问题时也能看出一些东西。
有的服务商会说明是大面积波动、单个 key 问题、临时资源紧张,还是长期不可用。有的服务商只会反复打哈哈,把所有问题都推给“上游”。
这些都不能证明它一定是真 Claude,也不能还原背后的资源链路。但它们能帮用户判断:这个中转站适不适合长期放进 Claude Code 工作流里。
这篇文章不讨论怎么让中转站公开底牌。现实里很难。
更现实的问题是,在一个链路不透明、资源会变化、真伪难以一次性验证的市场里,用户怎么建立自己的判断。
链路黑箱会直接影响开发体验
很多人聊中转站,容易只看价格。
价格当然重要。Claude Code 一旦高频使用,消耗并不低。便宜的中转站确实有吸引力。
价格之外,更实际的问题是:这个入口能不能长期稳定地放进开发流程里。
如果 Claude Code 只是偶尔拿来问几句,链路不稳定的影响没那么大。可一旦你真的把它当 coding agent 用,情况就不一样了。
它会参与读代码、改代码、跑测试、修报错。任务越复杂,越依赖连续性。
中转站背后的资源一旦频繁波动,开发者感受到的就是任务中断、工具调用失败、晚高峰变慢、模型手感变化。
这些问题单独看都不一定致命,但反复发生会很消耗人。
Claude Code 最有价值的地方,是让开发者在一个连续状态里推进任务。
中转链路如果总是打断这个状态,便宜也会变得没那么便宜。
结尾
中转站的出现有现实原因。
Claude Code 的需求真实存在,官方路径又有明显限制。中转站把复杂资源包装成一个能用的入口,让很多国内开发者先用上了 Claude Code。
但入口越简单,背后的链路越容易被忽略。
对 Claude Code 用户来说,真正该关心的不只是价格和模型名,还有这条链路能不能稳定跑完任务,出了问题能不能大概说清楚。
我不太相信“一眼鉴别真假 Claude”的方法。
如果你也长期在 Claude Code 里使用中转站提供的 Claude,欢迎一起讨论:有没有更好的测试、验真、验伪方式?你通常怎么判断一个中转站到底靠不靠谱?
如果你也长期在 Claude Code 里使用中转站提供的 Claude,欢迎一起讨论有没有更好的测试、验真、验伪方式。